Python3.6 字符串变量拼接新方法
在python3.6中更新打印字符串变量占位的新方法
和shell中变量使用思维差不多
查看下面示例:
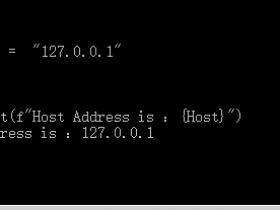
Host = "127.0.0.1"
Print(f"Host Address is :{Host}")
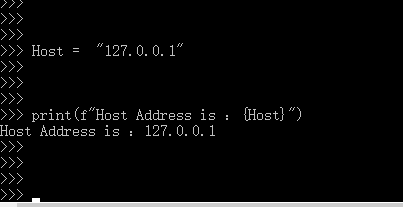
使用会更加方便,不在那么特别注意,变量插入顺序了
但是注意,插入的变量,还是得必须存在,使用不存在的变量还是会报错的。
>>> host1="127.0.0.1"
>>> port="3306"
>>> print(f"Host is :{host1},port is {port},user is {user}")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'user' is not defined
>>>
参考官网更新说明
参考地址
https://www.python.org/dev/peps/pep-0498/
In source code, f-strings are string literals that are prefixed by the letter 'f' or 'F'. Everywhere this PEP uses 'f', 'F' may also be used. 'f' may be combined with 'r' or 'R', in either order, to produce raw f-string literals. 'f' may not be combined with 'b': this PEP does not propose to add binary f-strings. 'f' may not be combined with 'u'.
When tokenizing source files, f-strings use the same rules as normal strings, raw strings, binary strings, and triple quoted strings. That is, the string must end with the same character that it started with: if it starts with a single quote it must end with a single quote, etc. This implies that any code that currently scans Python code looking for strings should be trivially modifiable to recognize f-strings (parsing within an f-string is another matter, of course).
Once tokenized, f-strings are parsed in to literal strings and expressions. Expressions appear within curly braces '{' and '}'. While scanning the string for expressions, any doubled braces '{{' or '}}' inside literal portions of an f-string are replaced by the corresponding single brace. Doubled literal opening braces do not signify the start of an expression. A single closing curly brace '}' in the literal portion of a string is an error: literal closing curly braces must be doubled '}}' in order to represent a single closing brace.
The parts of the f-string outside of braces are literal strings. These literal portions are then decoded. For non-raw f-strings, this includes converting backslash escapes such as '\n', '\"', "\'", '\xhh', '\uxxxx', '\Uxxxxxxxx', and named unicode characters '\N{name}' into their associated Unicode characters [6].
Backslashes may not appear anywhere within expressions. Comments, using the '#' character, are not allowed inside an expression.
Following each expression, an optional type conversion may be specified. The allowed conversions are '!s', '!r', or '!a'. These are treated the same as in str.format(): '!s' calls str() on the expression, '!r' calls repr() on the expression, and '!a' calls ascii() on the expression. These conversions are applied before the call to format(). The only reason to use '!s' is if you want to specify a format specifier that applies to str, not to the type of the expression.
F-strings use the same format specifier mini-language as str.format. Similar to str.format(), optional format specifiers maybe be included inside the f-string, separated from the expression (or the type conversion, if specified) by a colon. If a format specifier is not provided, an empty string is used.
- 本文标签: python语言
- 本文链接: http://www.iamlk.cn/article/86
- 版权声明: 本文由Leonidax原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐



相关文章
关于
